AI - Gradient Descent Algorithm
Hey there! I’m Yumi—your friendly AI guide, and maybe just a little bit of a cupcake enthusiast too! 😉 I’m here to make learning about AI and machine learning fun, easy, and totally not intimidating. I love breaking down complex ideas so they’re easy to digest, just like a good recipe (which you’ll see I use a lot as an analogy!). Think of me as your digital bestie, here to help you understand the coolest tech out there while keeping things light and enjoyable. Let’s dive in and learn together—one tasty learning adventure at a time!
Table of Contents
- Table of Contents
- Gradient Descent and Cupcake Analogy
- What is Gradient Descent?
- Learning Rate: The Key Ingredient
- Stochastic vs. Batch Gradient Descent
- The Big Picture
- Key Takeaways
- Gradient Descent: Simple Terms Guide
Gradient Descent and Cupcake Analogy
Let me explain the analogy I’m using here. Imagine I’m whipping up a delightful batch of cupcakes just for you! Each time I make a batch, I’m guessing at the right combination of ingredients to get that perfect taste. This is just like how a machine learning model uses gradient descent to improve its accuracy: it starts with an initial guess, learns from feedback (or ‘loss’), and keeps adjusting its ‘recipe’ until it gets closer to the ideal solution. So, think of each iteration of learning as me trying to bake better and better cupcakes for you!
What is Gradient Descent?
Gradient descent is a fundamental algorithm in machine learning used to optimize models by minimizing the error (or loss). It’s like finding the fastest way down a hill to get to the lowest point—the “valley” that represents the best possible solution for our problem. Let’s break it down using our cupcake analogy!
Here’s how it goes:
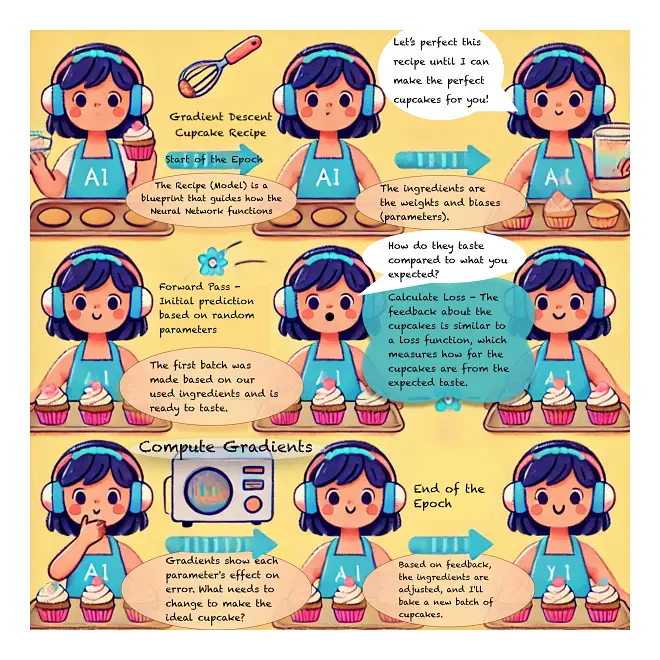
1. The First Batch (Forward Pass)
- I start with a random recipe, tossing in flour, sugar, butter—my starting “ingredients.” I don’t yet know if the recipe will be amazing or just okay, but it’s a place to begin.
- In this analogy, weights are like the main ingredients (flour, sugar, butter), while biases are like extra spices (vanilla, salt) that subtly adjust the flavor. Together, these “ingredients” affect how well the cupcakes will turn out.
- This initial recipe corresponds to the forward pass in a neural network, where it makes an initial prediction based on random parameters (weights and biases).
2. Taste Test (Calculate Loss and Backpropagation)
- I bake the cupcakes and give you a sample. You taste them and give feedback on what’s off (maybe they’re too sweet, too dense, or missing something).
- This feedback is like the loss function, measuring how far off my cupcakes are from the ideal taste—just as a neural network’s loss function measures the error in predictions.
3. Figuring Out What Went Wrong (Compute Gradients and Backpropagation)
- To improve, I need to figure out which ingredients caused the cupcakes to taste off. Maybe it’s too much sugar or not enough butter?
- This process is where gradients come in. They tell the network how much each parameter (weight or bias) contributed to the error. For me, gradients tell me how much each ingredient affected the taste.
4. Adjusting the Recipe (Update Parameters and Optimizer Functions)
- Based on your feedback, I adjust the recipe. I might add less sugar or increase the flour slightly to see if this brings me closer to the perfect cupcake.
- In neural networks, gradient descent works the same way by adjusting the parameters (weights and biases) in the direction that reduces the error, fine-tuning each “ingredient” in the recipe. To help with this process, optimizer functions are used. Optimizers are like special techniques or helpers that guide the adjustments more efficiently, ensuring we’re moving toward the ideal solution in the best possible way. Some common optimizers are SGD (Stochastic Gradient Descent), Adam, and RMSprop, each with their own special way of helping us make the right adjustments.
- Adjusting the ingredients in a recipe is kind of like picking a learning rate. If I go for a high learning rate, I might overshoot and end up with too much or too little of something for the perfect cupcake. On the flip side, if I take it too slow with a low learning rate, it could take forever to get it right, and we’d just end up starving in the process.
5. Repeat the Process (Epochs)
- I bake another batch with the adjusted recipe, get feedback, and keep tweaking and testing. Each batch gets me a little closer to the ideal taste.
- In a neural network, these iterations are called epochs, where the network repeats the gradient descent process to get closer to the “perfect recipe” (or accurate predictions).
Learning Rate: The Key Ingredient
Imagine that each time I adjust my recipe, I make small changes to the ingredients. If I change too much too quickly, the cupcakes might be completely different—maybe even worse! The learning rate in gradient descent is like deciding how much to adjust each ingredient. If it’s too high, I might overshoot the perfect recipe; if it’s too low, I’ll be making such small changes that it will take forever to get it right.
The learning rate needs to be just right, balancing between making progress and avoiding drastic changes that mess everything up.
Stochastic vs. Batch Gradient Descent
Just like making cupcakes, I can adjust my recipe in different ways:
- Batch Gradient Descent: Imagine I bake a whole bunch of cupcakes before getting feedback. This means I’m making changes based on a complete batch of feedback, but it takes time.
- Stochastic Gradient Descent (SGD): Instead of baking an entire batch, I adjust after every single cupcake! It’s faster, and I get feedback immediately, but the changes might be a bit more chaotic.
- Mini-Batch Gradient Descent: This is like getting feedback after a small group of cupcakes, finding a balance between the two methods above. It’s usually the sweet spot for most machine learning tasks.
The Big Picture
Gradient descent helps machine learning models “learn” by taking small steps towards minimizing their error. It’s a clever, iterative process of tasting, adjusting, and baking again. Just like I’m trying to get the perfect cupcakes for you, a neural network adjusts its parameters to make the most accurate predictions it can.
Key Takeaways
- Gradient Descent is an optimization technique that minimizes errors in machine learning models.
- Weights and Biases are like ingredients in a recipe; they influence the outcome.
- Loss Function measures how far off predictions are, like your feedback on the cupcakes.
- Learning Rate determines the size of each adjustment step.
- There are different types of gradient descent (Batch, Stochastic, Mini-Batch) to suit different needs.
By using gradient descent, we can gradually improve our models just like how I would refine a cupcake recipe—one delicious step at a time!
Gradient Descent: Simple Terms Guide
Basic Concepts
Gradient Descent
A way for computers to learn by making small improvements over and over, like tweaking a recipe until it’s just right.
Loss Function
A way to measure how wrong the computer’s answers are. Just like tasting a cupcake to see how close it is to being perfect.
Forward Pass
The first try at making a prediction. Like baking your first batch of cupcakes with a new recipe.
Backpropagation
The process of figuring out what went wrong and what needs to change. Like realizing your cupcakes are too sweet, so you need less sugar next time.
The Building Blocks
Weights
The important numbers that determine how the computer makes decisions. Like the main ingredients in your recipe (flour, sugar, butter).
Biases
Extra numbers that help fine-tune the computer’s decisions. Like adding a pinch of salt or vanilla to perfect your cupcake recipe.
Training Parts
Learning Rate
How big of changes you make each time. A big learning rate means making big changes to your recipe; a small one means tiny adjustments.
Epoch
One complete round of learning from all your training data. Like baking one complete batch of cupcakes and learning from how they turned out.
Batch
How many examples you look at before making changes:
- Full Batch: Looking at all examples at once
- Mini-Batch: Looking at a small group of examples
- Stochastic: Looking at just one example at a time
Ways to Learn
Stochastic Gradient Descent (SGD)
Making changes after looking at just one example. Like adjusting your recipe after tasting just one cupcake.
Mini-Batch Gradient Descent
Making changes after looking at a small group of examples. Like adjusting your recipe after tasting a few cupcakes.
Optimizer Functions
Special tools that help decide how to make changes. Like having a master baker guide you on how to adjust your recipe.
Measuring Progress
Gradients
Arrows that point to which direction would make things better. Like knowing whether to add more or less of each ingredient.
Loss/Error
How far off your answers are from being correct. Like how different your cupcakes taste from the perfect cupcake.
Common Challenges
Local Minima
Getting stuck at “good enough” when something better exists. Like settling for an okay recipe when a better one is possible.
Global Minimum
The best possible solution. Like finding the perfect cupcake recipe that can’t be improved anymore.
Convergence
When you’ve reached a point where making more changes doesn’t help much. Like when your cupcakes are so good that tiny recipe changes don’t make them noticeably better.
Overfitting
When the computer learns the examples too exactly and can’t handle new situations. Like creating a recipe that only works with one specific brand of flour and fails with any other brand.
Learning Rate Decay
Gradually making smaller and smaller changes as you get closer to the right answer. Like making tinier adjustments to your recipe as it gets nearly perfect.